A lot of AWS work starts with the wrong question.
Teams ask, “Can someone come fix this?” or “Should we get a retainer?” before they have a clear picture of what is actually broken, what is merely annoying, and what the internal team can handle with a better plan.
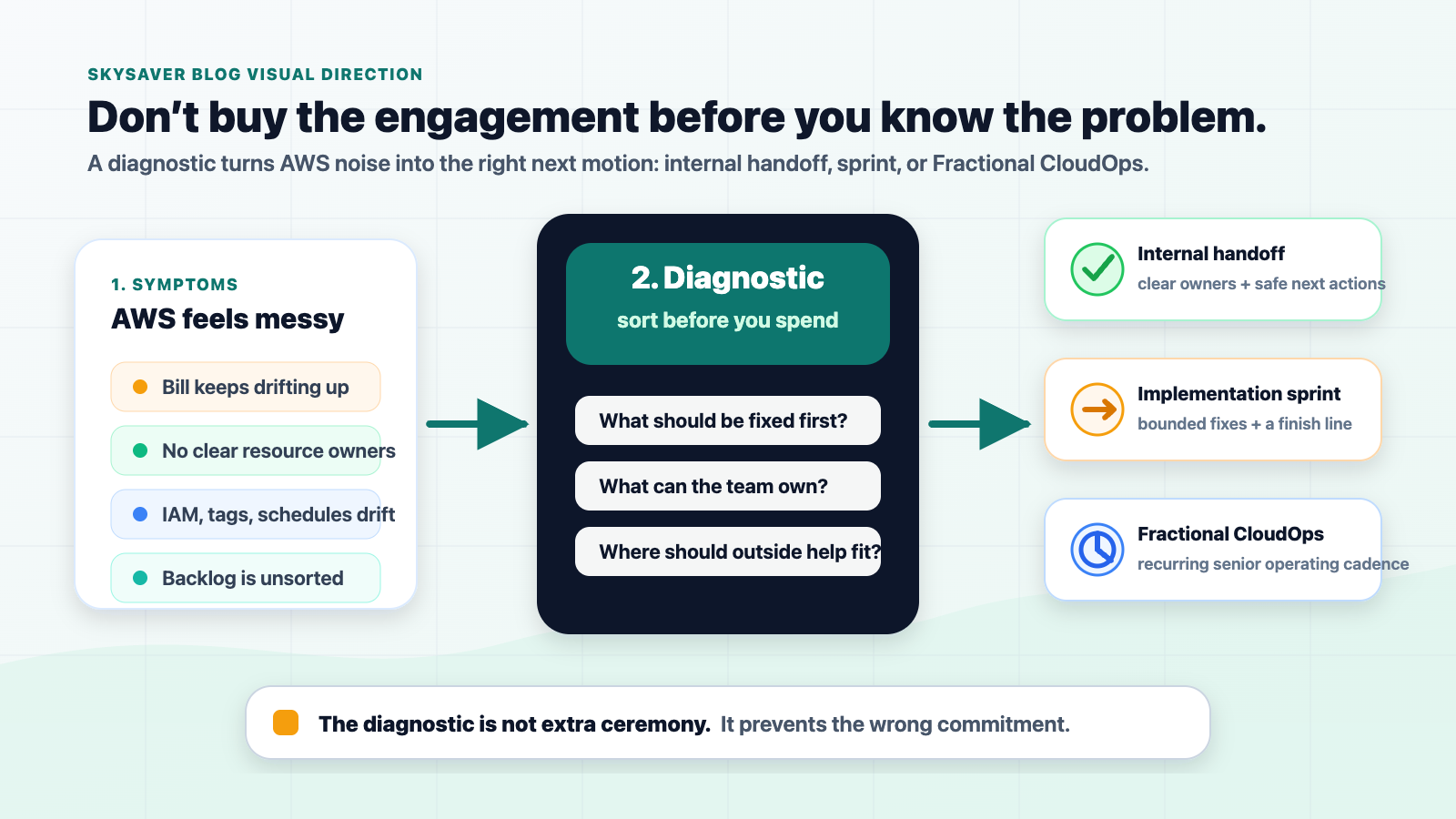
That is where an AWS CloudOps diagnostic helps. It gives the team a structured read on the environment before committing to an implementation sprint, recurring Fractional CloudOps support, or an internal handoff.
The point is not to slow the work down. The point is to avoid starting a sprint with vague goals, buying recurring support for a short-term cleanup problem, or handing engineers a backlog that still needs prioritization.
Why the diagnostic comes first
A diagnostic is useful when the team can feel AWS friction but does not yet have a clean action plan.
That friction can show up as rising spend, unclear account ownership, inconsistent tagging, IAM sprawl, non-production environments left running, or engineers spending too much time on manual operational work. Each symptom may be real, but they do not all need the same response.
Some issues need a quick implementation sprint. Some need ongoing operating rhythm. Some are better handled internally once the right priorities are clear. A diagnostic separates those paths.
For SkySaver, the diagnostic sits before the larger engagement because it answers practical questions:
- What should be fixed first?
- Which AWS problems are cost problems, operational problems, or both?
- Which changes are safe enough to make now?
- Which work needs architecture context before anyone touches it?
- What can the internal team own without outside support?
- Where would outside implementation help move faster?
Without that step, a sprint can become a grab bag. A retainer can become vague advisory time. An internal handoff can become another backlog nobody has time to sort.
The diagnostic is the sorting mechanism.
Signs you are not ready for a sprint yet
An implementation sprint works best when the problem is defined. If the team only has a general sense that AWS is messy or expensive, start with a diagnostic.
You are probably not ready for a sprint yet if any of these sound familiar:
- Nobody agrees on the top three AWS priorities.
- The team knows the bill is high, but not which services, accounts, workloads, or usage patterns are driving it.
- Tagging exists in some places but cannot support reliable ownership or reporting.
- IAM has accumulated exceptions, old users, broad permissions, or unclear role boundaries.
- Non-production environments are treated inconsistently across teams.
- Engineering, finance, and leadership are using different language to describe the same cloud problems.
- The backlog contains a mix of cleanup, automation, security, architecture, and cost items with no ranking.
- The team is not sure whether it needs hands-on implementation or just a better plan.
A sprint can still happen after this. It will be stronger if the diagnostic narrows the work first.
For example, “clean up AWS costs” is not a sprint. “Add schedules for selected non-production resources, tighten tagging rules for shared environments, and produce a handoff for recurring cost review” is much closer.
The diagnostic turns the first version into the second.
When an implementation sprint is the right next step
A sprint is the right fit when the diagnostic finds a bounded set of changes that can be implemented without turning into a permanent operating model.
That might include work like:
- creating or improving resource schedules for known non-production workloads
- cleaning up obvious unused resources after owner review
- improving tagging coverage for specific accounts or workloads
- tightening a small set of IAM roles or access patterns
- building a lightweight report or automation to make recurring review easier
- documenting a specific runbook the internal team can use going forward
The key word is bounded. The team should know what is in scope, what is out of scope, and what would make the sprint successful.
A good sprint does not need to solve every AWS problem. It should remove a specific blocker, reduce a specific source of waste or risk, or create the operational plumbing the team needs for the next phase.
If the diagnostic points to that kind of work, SkySaver’s services page is the natural next stop. The engagement can move from assessment into execution without pretending the team needs recurring support forever.
When Fractional CloudOps is the better fit
Fractional CloudOps makes more sense when the diagnostic shows that the problem is not a one-time cleanup. It is an operating cadence problem.
That usually looks like an environment where AWS keeps changing, but no one has enough senior CloudOps time to keep the work organized. New workloads appear. Old environments linger. IAM decisions pile up. Finance asks why spend changed. Engineering needs better automation. Leadership wants control, but not another full-time hire yet.
In that situation, a sprint may help with the first batch of work, but the pattern will return unless someone keeps the loop running.
Fractional CloudOps is a better fit when the team needs recurring help with:
- prioritizing the AWS operations backlog
- reviewing cost, ownership, and usage patterns on a regular cadence
- turning cloud governance ideas into practical AWS changes
- supporting engineers on architecture, automation, and implementation choices
- deciding which work belongs inside the team and which should be handled externally
- keeping cost control connected to how the environment is actually operated
This is not the same as 24/7 managed service coverage. It is senior AWS CloudOps support on a recurring basis, usually alongside the internal team.
If that is the shape of the problem, the next step is usually to look at Fractional CloudOps rather than treating every issue as a one-off project.
What a good diagnostic should produce
A diagnostic should leave the team with more than a meeting summary.
At minimum, it should produce a clear readout that the team can act on. The format can vary, but the substance should answer a few basic questions.
What did we review? The readout should name the AWS areas covered, such as accounts, cost patterns, IAM structure, tagging, automation, non-production usage, or operational workflows.
What did we find? The findings should be specific enough that an engineer, finance lead, or founder can understand what is happening without decoding consultant language.
What should happen next? The output should separate quick wins from deeper work. It should also say what not to touch yet if the risk or context is not clear.
Who should own it? Some work belongs with the internal team. Some work may need outside implementation. Some work may belong in a recurring CloudOps cadence.
What is the decision path? The readout should help the team choose one of three routes:
- internal execution with a clear handoff
- a focused implementation sprint
- recurring Fractional CloudOps support
SkySaver’s sample savings report gives a sense of how findings can be organized and explained. Treat it as an illustrative example, not proof of a specific customer result.
What to do after the readout
The readout should create a decision, not another vague discussion.
A practical next step usually falls into one of three paths.
First, the internal team may take the work. This is the right answer when the diagnostic creates enough clarity and the team has the time, access, and AWS experience to execute safely. In that case, the best outcome is a clean handoff: priorities, notes, risks, and ownership.
Second, the team may choose an implementation sprint. This is the right answer when the work is well defined but the team needs help getting it done. The sprint should have clear scope and a finish line.
Third, the team may move into Fractional CloudOps. This is the right answer when the diagnostic shows a recurring pattern: AWS keeps creating operational, automation, and cost-control work that needs steady senior attention.
The diagnostic can also reveal that now is not the right time to engage. That is still useful. If access is not available, ownership is unclear, or the business is not ready to act on recommendations, forcing a sprint or retainer will not help much.
When SkySaver is probably not the right fit
SkySaver is not the right fit for every AWS problem.
If you need around-the-clock ticket coverage, a general-purpose MSP may be a better match. If you need deep application development, a product engineering firm may be the right path. If the team only needs someone to rubber-stamp decisions already made, a diagnostic will probably feel unnecessary.
SkySaver is a better fit when you want a senior, practical read on your AWS environment and a clear path from findings to action. That may mean internal execution, a focused sprint, or recurring Fractional CloudOps support.
The diagnostic is the first step because it keeps the engagement honest. It helps answer the question before the commitment gets bigger: what kind of AWS help do you actually need right now?
If that is the question your team is trying to answer, start with the qualification form. Share what is happening in AWS, what feels stuck, and what kind of decision you need to make. The diagnostic can help turn that into a plan.